



12 Factor App Revisited
The Twelve-Factor App methodology is a methodology for building software-as-a-service applications by Adam Wiggins. We cover how they have since evolved, and what we can learn from them today and how they changed the status quo of yesteryear.


You will often see the good ol' days of software development and deployment being touted as better. The current reincarnation of this trend is Heroku. Don't get me wrong, Heroku was incredible and led to a new way of writing web applications and deploying about distributed systems. Looks like they got a lot of it right. If over 10 years later we are trying to capture the same ease of development.
A notable write-up by Heroku's co-founder Adam Wiggins was the 12 Factor App, which summarized a lot of the ideas which made using and, I am sure, building Heroku fun and rewarding.
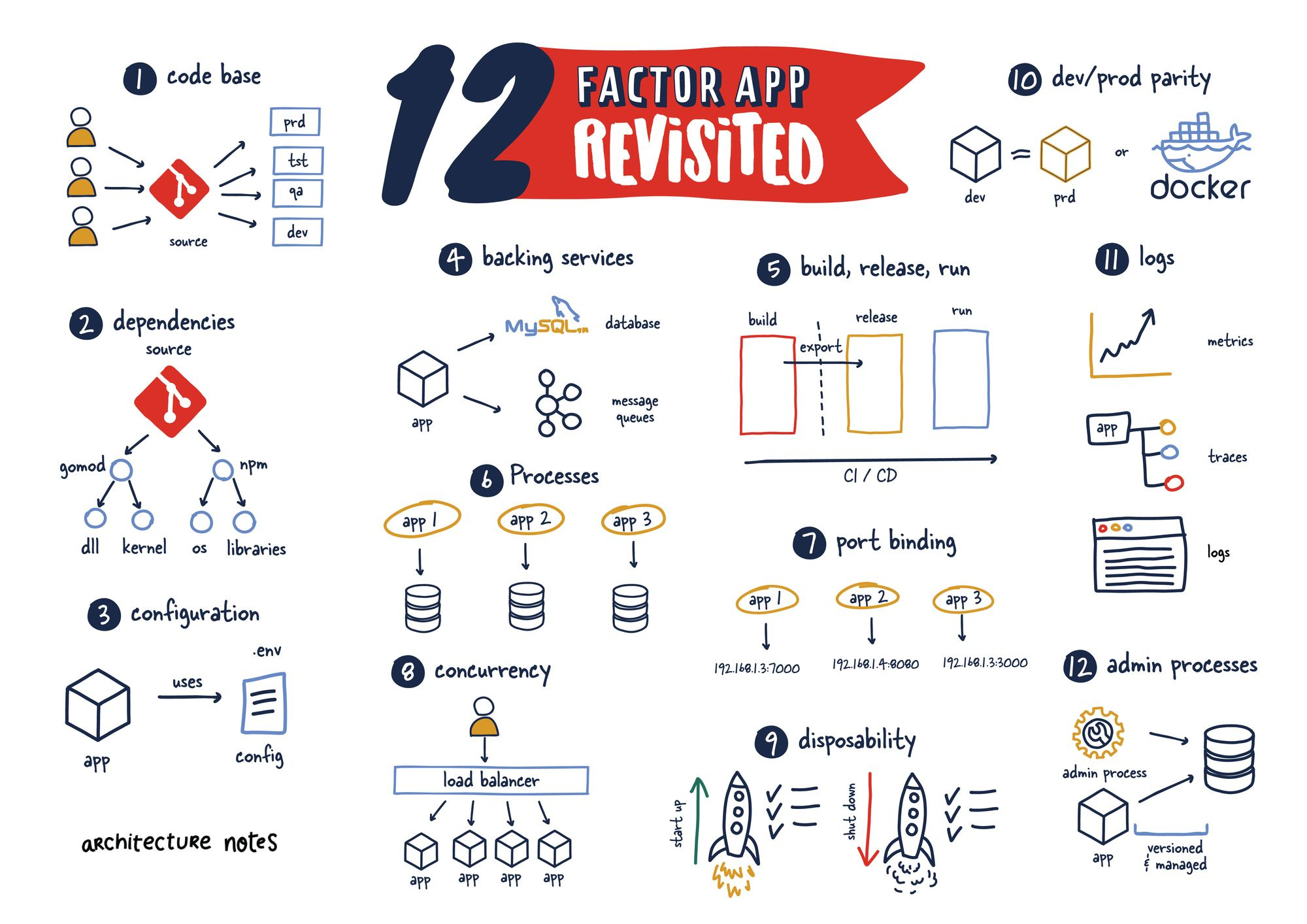
In this post, I want to go over each of the 12 factors Adam covered, how they have since evolved, what we can learn from them today and how they changed the status quo of yesteryear.
Codebase

When this advice was reared, things like Github were just getting started, and it wasn't commonplace to assume code was being versioned. It might seem brutal, but it is true. I remember having to deal with issues with Subversion when I was getting started.
The relationship between code repositories and their applications has grown significantly, including everything from testing to deployment. However, one point that remains highly contentious is the monorepo or not.
If there are multiple codebases, it’s not an app – it’s a distributed system. Each component in a distributed system is an app, and each can individually comply with twelve-factor.
Especially in a microservices-focused world, all the overhead needed to maintain multiple repositories can be tiresome.
Dependencies

I am not entirely sure how many of you had to deal with provisioning systems before the availability of software like Ansible and Puppet. Still, the peculiarity between operating systems and various versions of libraries was an absolute nightmare.
This factor nailed it right on the head and ultimately can be seen as a solved problem for the most part.
With this introduction of various manifest files, our application can be rebuilt with consistency and accuracy. Furthermore, build tools like Bazel have taken it further to include many powerful tools for build engineers to create reproducible releases. Not to mention we can now ship simple images that package strictly what we need to deploy in production (more on that later).
Configuration

This factor has remained unchanged, but a few things to consider when ensuring configuration is separate from the application code. First, as tools take a more opinionated approach, these choices are being moved more and more towards tools like Vault or service discovery systems which manage and store configuration in environment-aware systems.
Backing Services

Initially, this factor was primarily written around a single system's components, mainly focused on databases and the like. Even though it doesn't mention any difference between local and third-party systems, this has been taken further when building a system that others will leverage as a platform with an API-first approach. This approach was so successful that many teams started adopting this strategy to create a clean contract between teams responsible for different areas of the systems. This ultimately promotes flexibility and efficiency as these systems grow.
Build, Release, Run

This factor is pretty much par for any modern service being developed today. Something I would like to point out that I see not happen regularly is the split between the build and release steps, which is crucial to making sane deployment and rollback flows.
As code is merged and tested, each build result image (or binary) should be stored by some mechanism where it can be requested for later release and deployment. This separation allows for a simpler and less error-prone development cycle.
This may not be necessary at more minor scales or earlier in the development cycle, where these changes are tightly coupled to the development of the application and its infrastructure. GitOps is an area where a lot of the concepts are discussed further.
Processes

As written, this factor remains relevant in the world of REST APIs. In the case of web services, this means that we should never retain a domain state in memory between requests. Instead, all communication across these applications should remain stateless or stored in another backing system.
The number of scaling issues all systems face is the management and storage of state. This is very important for scaling out in a software-as-a-service model. This also goes well with the concept of bounded context, which ensures that each system should manage its storage layer and if other systems need to access that data, it should do so through a well-documented API.
Port Binding

This factor has been standard practice for some time, and nothing has changed meaningfully here. Furthermore, this factor has been enforced by many containerization standards and proxies and load balancers.
The main idea is that each application should have a specific port mapping.
Often the selected port can communicate information to be expected on a said port. This is only possible with network mapping of containers to hosts. The concept of port binding is that using a uniform port number can be the best method to expose a process to a network. For instance, port 80 is the default for web servers when running under HTTP. Similarly, when running under SSH, port 22 is the default.
Concurrency

The concurrency factor is that the application should organize each process according to its purpose. Engineers can achieve this through the separation of those processes into different groups.This factor summarizes various attributes of horizontal scaling and newer entrants into this space, such as functions as a service. For example, knowing that many machines are much more capable than a few larger machines for specific workloads.
Another key takeaway is that applications should do this concurrency around their workload, and applications with competing workloads should be broken out and scaled independently.
Disposability

This factor is an essential element that I often see overlooked until the system requires it. Start-up checks are crucial to ensure systems are operating and functional. Health checks ensure the system continues in this state or sees itself removed from rotation.
I see the same lack of care during the shutdown process; it's relatively complex and hard to do right, coupled with the age-old argument of 'what does it matter if we do it cleanly? It won't survive the process.'. Well, if not done correctly in a distributed system, it can have cascading effects on other systems that rely on it. Additionally, if ignored can lead to degraded system reliability and, eventually, customer impact.
Development/Production Parity

As I see it, this factor is getting worse as we move more of our infrastructure into private clouds with vendor lock-in. Of course, things like Docker and Kubernetes make running our systems in both environments equivalent from an operational standpoint, but that hardly is the case when we get to the brass tax of it.
Anyone who has had to debug an issue reproducible in production can regale you of this nightmare of a situation. Unfortunately, insert private cloud providers have minimal incentive to make their technology public, and in fact (as a service), it is one of the best selling points.
Furthermore, attempting to fit all those systems on a machine readily available to all developers, Sisyphean struggle in itself.
Logs

This factor has become its industry even though the way Adam wrote the factor made it seem like it was someone else's problem. This has primarily changed from something done with the output of applications (logs) to something applications should concern themselves with absolutely.
As applications evolve, they will need to track logs, metrics and traces to truly understand and maintain their systems as they grow. Therefore, this factor likely needs to be updated to reflect application should be observable without the need to modify said system.
Admin Processes

Anything that changes the state of an application should be managed with the same vigour and process as the application itself. They should be tested and reviewed. It's hard to ensure this and shockingly easy to do when you are under the gun. I believe this can account for a shockingly high number of outages and uncomfortable retros.
More mature languages with available frameworks give easy mechanisms to create and test these admin processes. However, if you work in a language that doesn't provide these on ramps, you must create them. This includes migration processes, dependency management, and even one-off processes for clean-up and management.
References
The Twelve-Factor App